486-16-15")
Скриншот ошибки на сайте Admitad
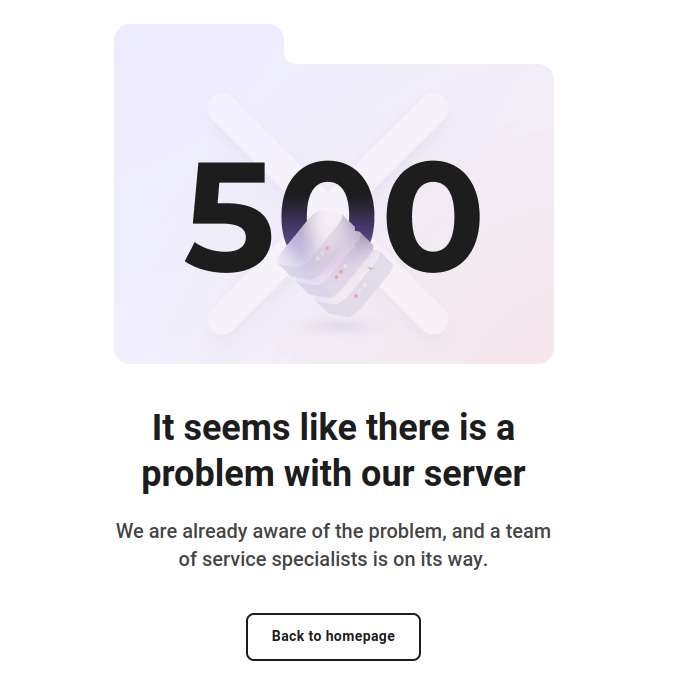
Ошибки в работе веб-сервисов неизбежны, и это нормально. Сложность современных систем, множество интеграций и высокая динамика изменений создают условия, при которых сбоев не избежать. Важно не столько пытаться предотвратить все ошибки, сколько быть готовым быстро и эффективно с ними справляться.
Как справляться с ошибками в веб-сервисах:
1.Проактивный мониторинг и оповещения Современные системы мониторинга позволяют отслеживать состояние сервиса в режиме реального времени. С их помощью можно заранее обнаруживать отклонения в работе и получать уведомления о потенциальных сбоях ещё до того, как они повлияют на пользователей.
Отказоустойчивые системы Архитектуры с балансировкой нагрузки, автоматическим переключением на резервные сервера и изоляцией компонентов помогают снизить риск полной остановки сервиса. Микросервисы и распределенные системы делают сервис более гибким и устойчивым к сбоям.
Обработка ошибок и восстановление Важно проектировать систему так, чтобы она могла быстро восстанавливаться после ошибок. Это может включать автоматический перезапуск процессов, откат на предыдущие версии, либо временную изоляцию проблемных компонентов для предотвращения каскадных сбоев.
План реагирования на инциденты Наличие чёткого плана на случай сбоя позволяет команде быстро реагировать на инциденты. Регулярные тренировки и анализ прошедших сбоев (post-mortem) помогают команде быть всегда готовой к решению критических проблем.
Коммуникация с пользователями Прозрачность важна. В случае серьёзного сбоя необходимо своевременно информировать пользователей о проблеме, предпринимаемых мерах и примерных сроках восстановления. Это помогает сохранить доверие и снизить недовольство.
Вывод
Ошибки — это неизбежная часть работы любого веб-сервиса. Ключ к успеху заключается в способности быстро выявлять и устранять проблемы, минимизируя их влияние на пользователей. Надёжная архитектура, мониторинг и готовность к инцидентам позволяют поддерживать высокий уровень доступности и стабильности сервиса.